History
September 2008: updated for Version 1.5.
October 2007: updated for Version 1.2.
January 2006: first version.
The purpose of this document is to tell how to implement the GF resource grammar API for a new language. We will not cover how to use the resource grammar, nor how to change the API. But we will give some hints how to extend the API.
A manual for using the resource grammar is found in
www.cs.chalmers.se/Cs/Research/Language-technology/GF/lib/resource/doc/synopsis.html.
A tutorial on GF, also introducing the idea of resource grammars, is found in
www.cs.chalmers.se/Cs/Research/Language-technology/GF/doc/gf-tutorial.html.
This document concerns the API v. 1.5, while the current stable release is 1.4. You can find the code for the stable release in
www.cs.chalmers.se/Cs/Research/Language-technology/GF/lib/resource/
and the next release in
www.cs.chalmers.se/Cs/Research/Language-technology/GF/next-lib/src/
It is recommended to build new grammars to match the next release.
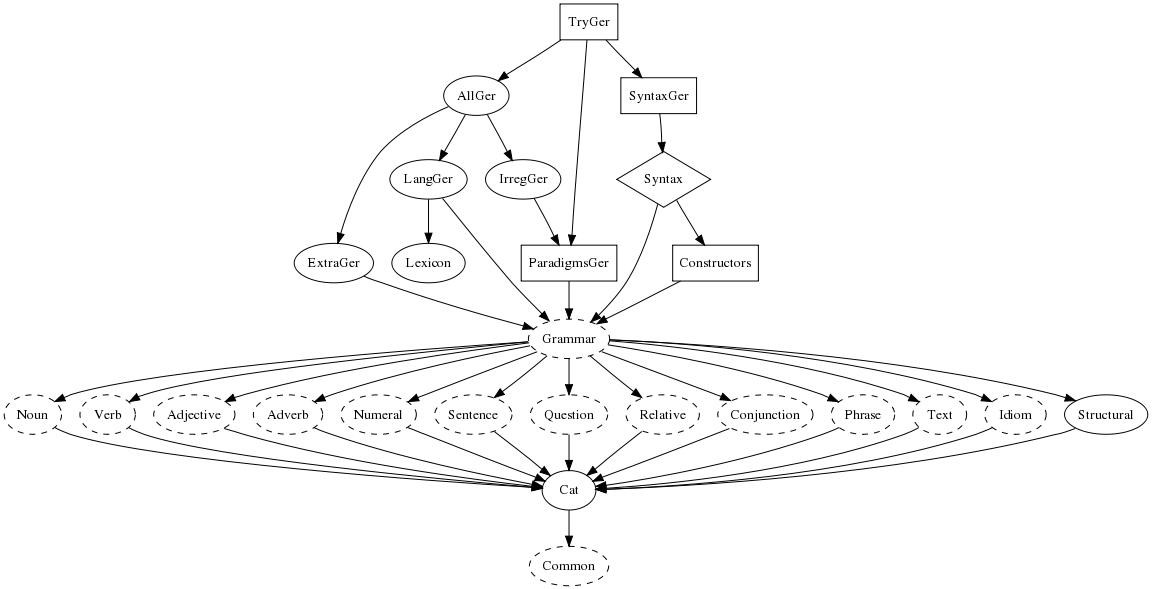
The library is divided into a bunch of modules, whose dependencies are given in the following figure.
Modules of different kinds are distinguished as follows:
Put in another way:
The dashed ellipses form the main parts of the implementation, on which the resource
grammar programmer has to work with. She also has to work on the Paradigms
module. The rest of the modules can be produced mechanically from corresponding
modules for other languages, by just changing the language codes appearing in
their module headers.
The module structure is rather flat: most modules are direct
parents of Grammar. The idea
is that the implementors can concentrate on one linguistic aspect at a time, or
also distribute the work among several authors. The module Cat
defines the "glue" that ties the aspects together - a type system
to which all the other modules conform, so that e.g. NP means
the same thing in those modules that use NPs and those that
constructs them.
For the user of the library, these modules are the most important ones.
In a typical application, it is enough to open Paradigms and Syntax.
The module Try combines these two, making it possible to experiment
with combinations of syntactic and lexical constructors by using the
cc command in the GF shell. Here are short explanations of each API module:
Try: the whole resource library for a language (Paradigms, Syntax,
Irreg, and Extra);
produced mechanically as a collection of modules
Syntax: language-independent categories, syntax functions, and structural words;
produced mechanically as a collection of modules
Constructors: language-independent syntax functions and structural words;
produced mechanically via functor instantiation
Paradigms: language-dependent morphological paradigms
The immediate parents of Grammar will be called phrase category modules,
since each of them concentrates on a particular phrase category (nouns, verbs,
adjectives, sentences,...). A phrase category module tells
how to construct phrases in that category. You will find out that
all functions in any of these modules have the same value type (or maybe
one of a small number of different types). Thus we have
Noun: construction of nouns and noun phrases
Adjective: construction of adjectival phrases
Verb: construction of verb phrases
Adverb: construction of adverbial phrases
Numeral: construction of cardinal and ordinal numerals
Sentence: construction of sentences and imperatives
Question: construction of questions
Relative: construction of relative clauses
Conjunction: coordination of phrases
Phrase: construction of the major units of text and speech
Text: construction of texts as sequences of phrases
Idiom: idiomatic expressions such as existentials
Expressions of each phrase category are constructed in the corresponding
phrase category module. But their use takes mostly place in other modules.
For instance, noun phrases, which are constructed in Noun, are
used as arguments of functions of almost all other phrase category modules.
How can we build all these modules independently of each other?
As usual in typeful programming, the only thing you need to know about an object you use is its type. When writing a linearization rule for a GF abstract syntax function, the only thing you need to know is the linearization types of its value and argument categories. To achieve the division of the resource grammar to several parallel phrase category modules, what we need is an underlying definition of the linearization types. This definition is given as the implementation of
Cat: syntactic categories of the resource grammar
Any resource grammar implementation has first to agree on how to implement
Cat. Luckily enough, even this can be done incrementally: you
can skip the lincat definition of a category and use the default
{s : Str} until you need to change it to something else. In
English, for instance, many categories do have this linearization type.
What is lexical and what is syntactic is not as clearcut in GF as in
some other grammar formalisms. Logically, lexical means atom, i.e. a
fun with no arguments. Linguistically, one may add to this
that the lin consists of only one token (or of a table whose values
are single tokens). Even in the restricted lexicon included in the resource
API, the latter rule is sometimes violated in some languages. For instance,
Structural.both7and_DConj is an atom, but its linearization is
two words e.g. both - and.
Another characterization of lexical is that lexical units can be added almost ad libitum, and they cannot be defined in terms of already given rules. The lexical modules of the resource API are thus more like samples than complete lists. There are two such modules:
Structural: structural words (determiners, conjunctions,...)
Lexicon: basic everyday content words (nouns, verbs,...)
The module Structural aims for completeness, and is likely to
be extended in future releases of the resource. The module Lexicon
gives a "random" list of words, which enables testing the syntax.
It also provides a check list for morphology, since those words are likely to include
most morphological patterns of the language.
In the case of Lexicon it may come out clearer than anywhere else
in the API that it is impossible to give exact translation equivalents in
different languages on the level of a resource grammar. This is no problem,
since application grammars can use the resource in different ways for
different languages.
In addition to the common API, there is room for language-dependent extensions of the resource. The top level of each languages looks as follows (with German as example):
abstract AllGerAbs = Lang, ExtraGerAbs, IrregGerAbs
where ExtraGerAbs is a collection of syntactic structures specific to German,
and IrregGerAbs is a dictionary of irregular words of German
(at the moment, just verbs). Each of these language-specific grammars has
the potential to grow into a full-scale grammar of the language. These grammar
can also be used as libraries, but the possibility of using functors is lost.
To give a better overview of language-specific structures,
modules like ExtraGerAbs
are built from a language-independent module ExtraAbs
by restricted inheritance:
abstract ExtraGerAbs = Extra [f,g,...]
Thus any category and function in Extra may be shared by a subset of all
languages. One can see this set-up as a matrix, which tells
what Extra structures
are implemented in what languages. For the common API in Grammar, the matrix
is filled with 1's (everything is implemented in every language).
In a minimal resource grammar implementation, the language-dependent extensions are just empty modules, but it is good to provide them for the sake of uniformity.
Some lines in the resource library are suffixed with the comment
--# notpresent
which is used by a preprocessor to exclude those lines from a reduced version of the full resource. This present-tense-only version is useful for applications in most technical text, since they reduce the grammar size and compilation time. It can also be useful to exclude those lines in a first version of resource implementation. To compile a grammar with present-tense-only, use
make Present
with resource/Makefile.
Unless you are writing an instance of a parametrized implementation (Romance or Scandinavian), which will be covered later, the simplest way is to follow roughly the following procedure. Assume you are building a grammar for the German language. Here are the first steps, which we actually followed ourselves when building the German implementation of resource v. 1.0 at Ubuntu linux. We have slightly modified them to match resource v. 1.5 and GF v. 3.0.
GF/lib/resource/english, named
german.
cd GF/lib/resource/
mkdir german
cd german
Ger and Deu are given, and we pick Ger.
(We use the 3-letter codes rather than the more common 2-letter codes,
since they will suffice for many more languages!)
*Eng.gf files from english german,
and rename them:
cp ../english/*Eng.gf .
rename 's/Eng/Ger/' *Eng.gf
If you don't have the rename command, you can use a bash script with mv.
Eng module references to Ger references
in all files:
sed -i 's/English/German/g' *Ger.gf
sed -i 's/Eng/Ger/g' *Ger.gf
The first line prevents changing the word English, which appears
here and there in comments, to Gerlish. The sed command syntax
may vary depending on your operating system.
Eng - verify this by
grep Ger *.gf
But you will have to make lots of manual changes in all files anyway!
sed -i 's/^/--/' *Ger.gf
This will give you a set of templates out of which the grammar
will grow as you uncomment and modify the files rule by rule.
.gf files, uncomment the module headers and brackets,
leaving the module bodies commented. Unfortunately, there is no
simple way to do this automatically (or to avoid commenting these
lines in the previous step) - but uncommenting the first
and the last lines will actually do the job for many of the files.
sed -i 's/^--//' LangGer.gf
LangGer in GF:
gf LangGer.gf
You will get lots of warnings on missing rules, but the grammar will compile.
pg -missing
tells you what exactly is missing.
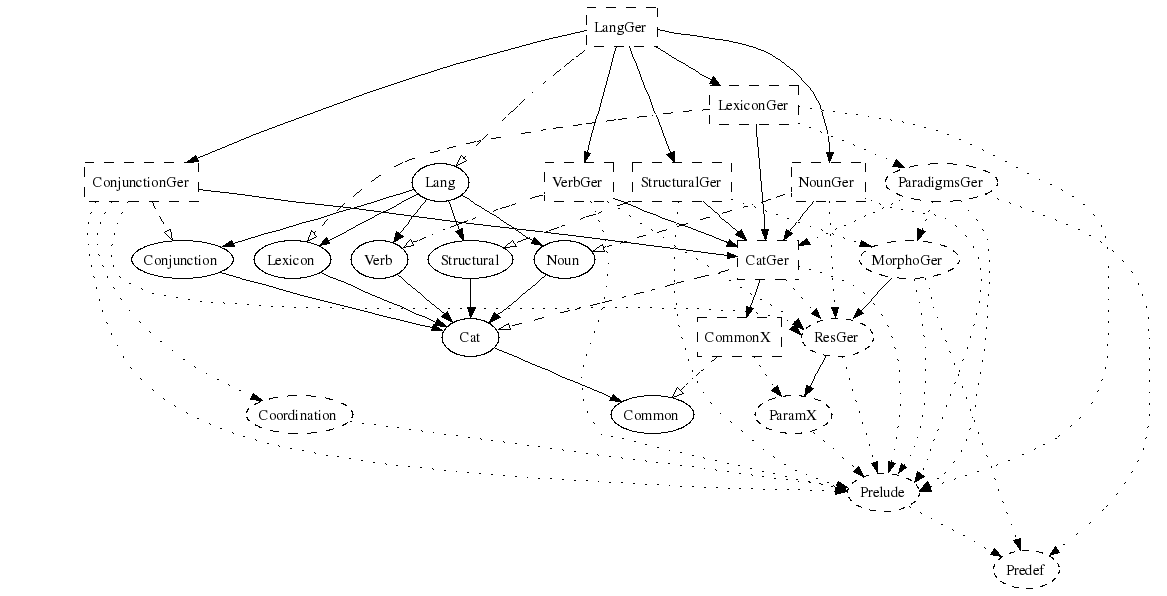
Here is the module structure of LangGer. It has been simplified by leaving out
the majority of the phrase category modules. Each of them has the same dependencies
as VerbGer, whose complete dependencies are shown as an example.
The real work starts now. There are many ways to proceed, the most obvious ones being
Phrase and go down to Sentence, then
Verb, Noun, and in the end Lexicon. In this way, you are all the time
building complete phrases, and add them with more content as you proceed.
This approach is not recommended. It is impossible to test the rules if
you have no words to apply the constructions to.
Lexicon. To this end, you
need to write ParadigmsGer, which in turn needs parts of
MorphoGer and ResGer.
This approach is not recommended. You can get stuck to details of
morphology such as irregular words, and you don't have enough grasp about
the type system to decide what forms to cover in morphology.
The practical working direction is thus a saw-like motion between the morphological and top-level modules. Here is a possible course of the work that gives enough test data and enough general view at any point:
Cat.N and the required parameter types in ResGer. As we define
lincat N = {s : Number => Case => Str ; g : Gender} ;
we need the parameter types Number, Case, and Gender. The definition
of Number in common/ParamX
works for German, so we
use it and just define Case and Gender in ResGer.
mkN in ParadigmsGer. In this way you can
already implement a huge amount of nouns correctly in LexiconGer. Actually
just adding the worst-case instance of mkN (the one taking the most
arguments) should suffice for every noun - but,
since it is tedious to use, you
might proceed to the next step before returning to morphology and defining the
real work horse, mkN taking two forms and a gender.
resource directory, by the commands
> i -retain german/ParadigmsGer
> cc -table mkN "Kirche"
NounGer (DetCN UsePron DetQuant NumSg DefArt IndefArt UseN) and
StructuralGer (i_Pron this_Quant). You also need some categories and
parameter types. At this point, it is maybe not possible to find out the final
linearization types of CN, NP, Det, and Quant, but at least you should
be able to correctly inflect noun phrases such as every airplane:
> i german/LangGer.gf
> l -table DetCN every_Det (UseN airplane_N)
Nom: jeder Flugzeug
Acc: jeden Flugzeug
Dat: jedem Flugzeug
Gen: jedes Flugzeugs
CatGer.V, ResGer.VForm, and
ParadigmsGer.mkV. You may choose to exclude notpresent
cases at this point. But anyway, you will be able to inflect a good
number of verbs in Lexicon, such as
live_V (mkV "leben").
VP and
Cl in CatGer, VerbGer.UseV, and SentenceGer.PredVP.
Even if you have excluded the tenses, you will be able to produce
> i -preproc=./mkPresent german/LangGer.gf
> l -table PredVP (UsePron i_Pron) (UseV live_V)
Pres Simul Pos Main: ich lebe
Pres Simul Pos Inv: lebe ich
Pres Simul Pos Sub: ich lebe
Pres Simul Neg Main: ich lebe nicht
Pres Simul Neg Inv: lebe ich nicht
Pres Simul Neg Sub: ich nicht lebe
You should also be able to parse:
> p -cat=Cl "ich lebe"
PredVP (UsePron i_Pron) (UseV live_V)
CatGer.V2 CatGer.VPSlash ParadigmsGer.mkV2 VerbGer.ComplSlash VerbGer.SlashV2a)
are a natural next step, so that you can
produce ich liebe dich ("I love you").
CatGer.A ParadigmsGer.mkA NounGer.AdjCN AdjectiveGer.PositA)
will force you to think about strong and weak declensions, so that you can
correctly inflect mein neuer Wagen, dieser neue Wagen
("my new car, this new car").
The following develop-test cycle will be applied most of the time, both in the first steps described above and in later steps where you are more on your own.
NounGer, and uncomment some
linearization rules (for instance, DetCN, as above).
CN, NP, N, Det) and the
variations they have. Encode this in the lincats of CatGer.
You may have to define some new parameter types in ResGer.
LexiconGer. You will also need some regular inflection patterns
inParadigmsGer.
treebank option
preserves the tree
> gr -cat=NP -number=20 | l -table -treebank
diff command to compare later
linearizations produced from the same list of trees. If you save the trees
in a file trees, you can do as follows:
> rf -file=trees -tree -lines | l -table -treebank | wf -file=treebank
resource/exx-resource.gft. A treebank can be created from this by
the Unix command
% runghc Make.hs test langs=Ger
You are likely to run this cycle a few times for each linearization rule
you implement, and some hundreds of times altogether. There are roughly
70 cats and
600 funs in Lang at the moment; 170 of the funs are outside the two
lexicon modules).
These auxuliary resource modules will be written by you.
ResGer: parameter types and auxiliary operations
(a resource for the resource grammar!)
ParadigmsGer: complete inflection engine and most important regular paradigms
MorphoGer: auxiliaries for ParadigmsGer and StructuralGer. This need
not be separate from ResGer.
These modules are language-independent and provided by the existing resource package.
ParamX: parameter types used in many languages
CommonX: implementation of language-uniform categories
such as $Text$ and $Phr$, as well as of
the logical tense, anteriority, and polarity parameters
Coordination: operations to deal with lists and coordination
Prelude: general-purpose operations on strings, records,
truth values, etc.
Predef: general-purpose operations with hard-coded definitions
An important decision is what rules to implement in terms of operations in
ResGer. The golden rule of functional programming says:
This rule suggests that an operation should be created if it is to be used at least twice. At the same time, a sound principle of vicinity says:
From these two principles, we have derived the following practice:
oper in ResGer. An example is mkClause,
used in Sentence, Question, and Relative-
Numerals.
let definition.
oper,
but rather inlined. However, a let definition may well be in place just
to make the readable.
Most functions in phrase category modules
are implemented in this way.
This discipline is very different from the one followed in early
versions of the library (up to 0.9). We then valued the principle of
abstraction more than vicinity, creating layers of abstraction for
almost everything. This led in practice to the duplication of almost
all code on the lin and oper levels, and made the code
hard to understand and maintain.
The paradigms needed to implement
LexiconGer are defined in
ParadigmsGer.
This module provides high-level ways to define the linearization of
lexical items, of categories N, A, V and their complement-taking
variants.
For ease of use, the Paradigms modules follow a certain
naming convention. Thus they for each lexical category, such as N,
the overloaded functions, such as mkN, with the following cases:
N. Its type signature
has the form
mkN : Str -> ... -> Str -> P -> ... -> Q -> N
with as many string and parameter arguments as can ever be needed to
construct an N.
mkN : Str -> N
For the complement-taking variants, such as V2, we provide
V and all necessary arguments, such
as case and preposition:
mkV2 : V -> Case -> Str -> V2 ;
Str and produces a transitive verb with the direct
object case:
mkV2 : Str -> V2 ;
mkV2 : V -> V2 ;
The golden rule for the design of paradigms is that
The discipline of data abstraction moreover requires that the user of the resource
is not given access to parameter constructors, but only to constants that denote
them. This gives the resource grammarian the freedom to change the underlying
data representation if needed. It means that the ParadigmsGer module has
to define constants for those parameter types and constructors that
the application grammarian may need to use, e.g.
oper
Case : Type ;
nominative, accusative, genitive, dative : Case ;
These constants are defined in terms of parameter types and constructors
in ResGer and MorphoGer, which modules are not
visible to the application grammarian.
An important difference between MorphoGer and
ParadigmsGer is that the former uses "raw" record types
for word classes, whereas the latter used category symbols defined in
CatGer. When these category symbols are used to denote
record types in a resource modules, such as ParadigmsGer,
a lock field is added to the record, so that categories
with the same implementation are not confused with each other.
(This is inspired by the newtype discipline in Haskell.)
For instance, the lincats of adverbs and conjunctions are the same
in CommonX (and therefore in CatGer, which inherits it):
lincat Adv = {s : Str} ;
lincat Conj = {s : Str} ;
But when these category symbols are used to denote their linearization types in resource module, these definitions are translated to
oper Adv : Type = {s : Str ; lock_Adv : {}} ;
oper Conj : Type = {s : Str} ; lock_Conj : {}} ;
In this way, the user of a resource grammar cannot confuse adverbs with conjunctions. In other words, the lock fields force the type checker to function as grammaticality checker.
When the resource grammar is opened in an application grammar, the
lock fields are never seen (except possibly in type error messages),
and the application grammarian should never write them herself. If she
has to do this, it is a sign that the resource grammar is incomplete, and
the proper way to proceed is to fix the resource grammar.
The resource grammarian has to provide the dummy lock field values
in her hidden definitions of constants in Paradigms. For instance,
mkAdv : Str -> Adv ;
-- mkAdv s = {s = s ; lock_Adv = <>} ;
The lexicon belonging to LangGer consists of two modules:
StructuralGer, structural words, built by using both
ParadigmsGer and MorphoGer.
LexiconGer, content words, built by using ParadigmsGer only.
The reason why MorphoGer has to be used in StructuralGer
is that ParadigmsGer does not contain constructors for closed
word classes such as pronouns and determiners. The reason why we
recommend ParadigmsGer for building LexiconGer is that
the coverage of the paradigms gets thereby tested and that the
use of the paradigms in LexiconGer gives a good set of examples for
those who want to build new lexica.
It is useful in most languages to provide a separate module of irregular
verbs and other words which are difficult for a lexicographer
to handle. There are usually a limited number of such words - a
few hundred perhaps. Building such a lexicon separately also
makes it less important to cover everything by the
worst-case variants of the paradigms mkV etc.
You can often find resources such as lists of
irregular verbs on the internet. For instance, the
Irregular German Verb page
previously found in
http://www.iee.et.tu-dresden.de/~wernerr/grammar/verben_dt.html
page gives a list of verbs in the
traditional tabular format, which begins as follows:
backen (du bäckst, er bäckt) backte [buk] gebacken
befehlen (du befiehlst, er befiehlt; befiehl!) befahl (beföhle; befähle) befohlen
beginnen begann (begönne; begänne) begonnen
beißen biß gebissen
All you have to do is to write a suitable verb paradigm
irregV : (x1,_,_,_,_,x6 : Str) -> V ;
and a Perl or Python or Haskell script that transforms the table to
backen_V = irregV "backen" "bäckt" "back" "backte" "backte" "gebacken" ;
befehlen_V = irregV "befehlen" "befiehlt" "befiehl" "befahl" "beföhle" "befohlen" ;
When using ready-made word lists, you should think about coyright issues. All resource grammar material should be provided under GNU Lesser General Public License (LGPL).
This is a cheap technique to build a lexicon of thousands of words, if text data is available in digital format. See the Extract Homepage homepage for details.
This is another cheap technique, where you need as input a list of words with
part-of-speech marking. You initialize the lexicon by using the one-argument
mkN etc paradigms, and add forms to those words that do not come out right.
This procedure is described in the paper
A. Ranta. How predictable is Finnish morphology? An experiment on lexicon construction. In J. Nivre, M. Dahllöf and B. Megyesi (eds), Resourceful Language Technology: Festschrift in Honor of Anna Sågvall Hein, University of Uppsala, 2008. Available from the series homepage
Sooner or later it will happen that the resource grammar API
does not suffice for all applications. A common reason is
that it does not include idiomatic expressions in a given language.
The solution then is in the first place to build language-specific
extension modules, like ExtraGer.
Above we have looked at how a resource implementation is built by the copy and paste method (from English to German), that is, formally speaking, from scratch. A more elegant solution available for families of languages such as Romance and Scandinavian is to use parametrized modules. The advantages are
Here is a set of slides on the topic.
This is the most demanding form of resource grammar writing.
We do not recommend the method of parametrizing from the
beginning: it is easier to have one language first implemented
in the conventional way and then add another language of the
same family by aprametrization. This means that the copy and
paste method is still used, but at this time the differences
are put into an interface module.
This section is relevant for languages using a non-ASCII character set.
From version 3.0, GF follows a simple encoding convention:
flags coding = utf8 ;
in each source module.
coding flag
gfo) and the Portable Grammar Format (pgf)
are in UTF-8
Most current resource grammars use isolatin-1 in the source, but this does not affect their use in parallel with grammars written in other encodings. In fact, a grammar can be put up from modules using different codings.
Warning. While string literals may contain any characters, identifiers must be isolatin-1 letters (or digits, underscores, or dashes). This has to do with the restrictions of the lexer tool that is used.
While UTF-8 is well supported by most web browsers, its use in terminals and text editors may cause disappointment. Many grammarians therefore prefer to use ASCII transliterations. GF 3.0beta2 provides the following built-in transliterations:
New transliterations can be defined in the GF source file
GF/Text/Transliterations.hs.
This file also gives instructions on how new ones are added.