lens: Lenses, Folds and Traversals
This package comes "Batteries Included" with many useful lenses for the types commonly used from the Haskell Platform, and with tools for automatically generating lenses and isomorphisms for user-supplied data types.
The combinators in Control.Lens provide a highly generic toolbox for composing
families of getters, folds, isomorphisms, traversals, setters and lenses and their
indexed variants.
An overview, with a large number of examples can be found in the README.
An introductory video on the style of code used in this library by Simon Peyton Jones is available from Skills Matter.
A video on how to use lenses and how they are constructed is available on youtube.
Slides for that second talk can be obtained from comonad.com.
More information on the care and feeding of lenses, including a brief tutorial and motivation for their types can be found on the lens wiki.
A small game of pong and other more complex examples that manage their state using lenses can be found in the example folder.
Lenses, Folds and Traversals
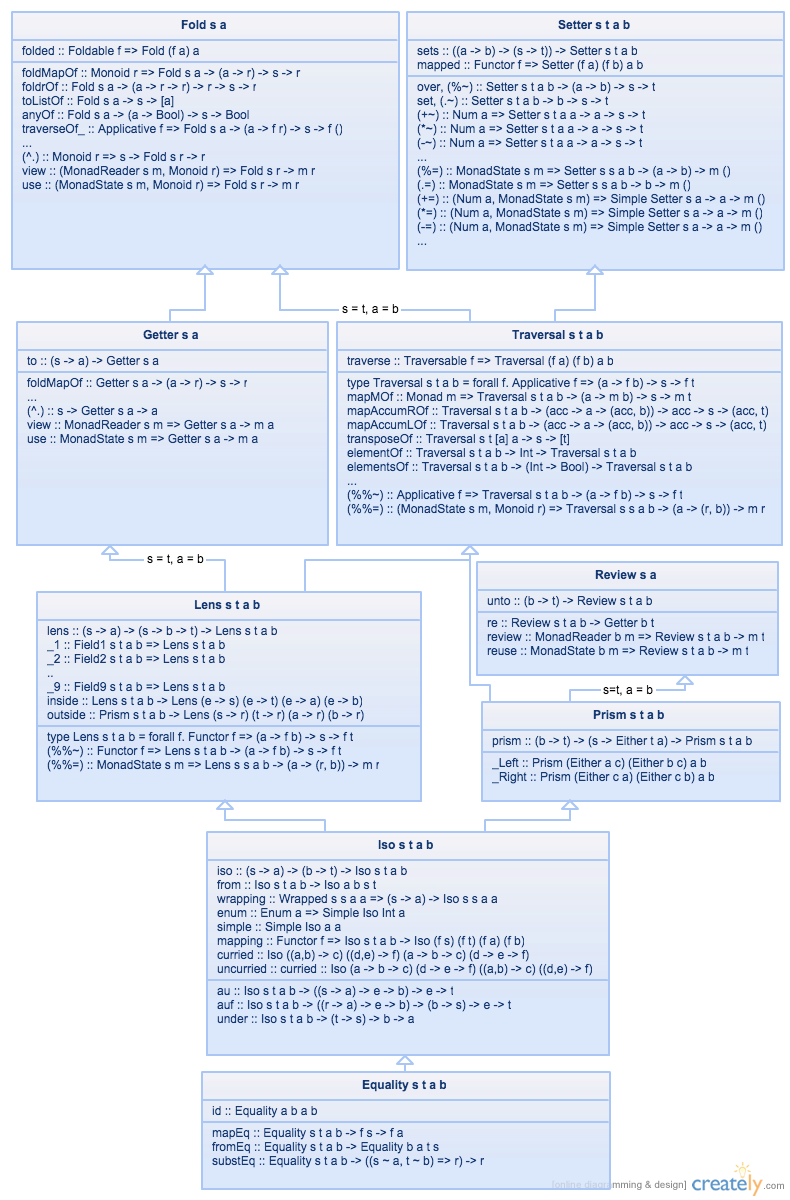
With some signatures simplified, the core of the hierarchy of lens-like constructions looks like:

{kind=link}
You can compose any two elements of the hierarchy above using (.) from the Prelude, and you can
use any element of the hierarchy as any type it linked to above it.
The result is their lowest upper bound in the hierarchy (or an error if that bound doesn't exist).
For instance:
You can use any
Traversalas aFoldor as aSetter.The composition of a
Traversaland aGetteryields aFold.
Minimizing Dependencies
If you want to provide lenses and traversals for your own types in your own libraries, then you can do so without incurring a dependency on this (or any other) lens package at all.
e.g. for a data type:
data Foo a = Foo Int Int a
You can define lenses such as
-- bar :: Lens' (Foo a) Int bar :: Functor f => (Int -> f Int) -> Foo a -> f (Foo a) bar f (Foo a b c) = fmap (\a' -> Foo a' b c) (f a)
-- quux :: Lens (Foo a) (Foo b) a b quux :: Functor f => (a -> f b) -> Foo a -> f (Foo b) quux f (Foo a b c) = fmap (Foo a b) (f c)
without the need to use any type that isn't already defined in the Prelude.
And you can define a traversal of multiple fields with Control.Applicative.Applicative:
-- traverseBarAndBaz :: Traversal' (Foo a) Int traverseBarAndBaz :: Applicative f => (Int -> f Int) -> Foo a -> f (Foo a) traverseBarAndBaz f (Foo a b c) = Foo <$> f a <*> f b <*> pure c
What is provided in this library is a number of stock lenses and traversals for common haskell types, a wide array of combinators for working them, and more exotic functionality, (e.g. getters, setters, indexed folds, isomorphisms).
[Skip to Readme]


Modules
[Index] [Quick Jump]
- Control
- Exception
- Control.Lens
- Control.Lens.At
- Control.Lens.Combinators
- Control.Lens.Cons
- Control.Lens.Each
- Control.Lens.Empty
- Control.Lens.Equality
- Control.Lens.Extras
- Control.Lens.Fold
- Control.Lens.Getter
- Control.Lens.Indexed
- Control.Lens.Internal
- Control.Lens.Internal.Bazaar
- Control.Lens.Internal.ByteString
- Control.Lens.Internal.CTypes
- Control.Lens.Internal.Coerce
- Control.Lens.Internal.Context
- Control.Lens.Internal.Deque
- Control.Lens.Internal.Exception
- Control.Lens.Internal.FieldTH
- Control.Lens.Internal.Fold
- Control.Lens.Internal.Getter
- Control.Lens.Internal.Indexed
- Control.Lens.Internal.Instances
- Control.Lens.Internal.Iso
- Control.Lens.Internal.Level
- Control.Lens.Internal.List
- Control.Lens.Internal.Magma
- Control.Lens.Internal.Prism
- Control.Lens.Internal.PrismTH
- Control.Lens.Internal.Review
- Control.Lens.Internal.Setter
- Control.Lens.Internal.TH
- Control.Lens.Internal.Typeable
- Control.Lens.Internal.Zoom
- Control.Lens.Iso
- Control.Lens.Lens
- Control.Lens.Level
- Control.Lens.Operators
- Control.Lens.Plated
- Control.Lens.Prism
- Control.Lens.Reified
- Control.Lens.Review
- Control.Lens.Setter
- Control.Lens.TH
- Control.Lens.Traversal
- Control.Lens.Tuple
- Control.Lens.Type
- Control.Lens.Unsound
- Control.Lens.Wrapped
- Control.Lens.Zoom
- Monad
- Parallel
- Strategies
- Seq
- Data
- Array
- Bits
- ByteString
- Complex
- Data
- Dynamic
- HashSet
- IntSet
- List
- Map
- Sequence
- Set
- Text
- Tree
- Typeable
- Vector
- GHC
- Generics
- Language
- Haskell
- Numeric
- System
- Exit
- FilePath
- IO
- Error
Flags
Manual Flags
| Name | Description | Default |
|---|---|---|
| benchmark-uniplate | Disabled | |
| inlining | Enabled | |
| old-inline-pragmas | Disabled | |
| dump-splices | Disabled | |
| test-doctests | Enabled | |
| test-hunit | Enabled | |
| test-properties | Enabled | |
| test-templates | Enabled | |
| safe | Disabled | |
| trustworthy | Enabled | |
| j | Disabled |
Use -f <flag> to enable a flag, or -f -<flag> to disable that flag. More info
Downloads
- lens-4.19.2.tar.gz [browse] (Cabal source package)
- Package description (revised from the package)
Note: This package has metadata revisions in the cabal description newer than included in the tarball. To unpack the package including the revisions, use 'cabal get'.
Maintainer's Corner
For package maintainers and hackage trustees
Candidates
- No Candidates
| Versions [RSS] | 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.0.1, 1.0.2, 1.0.3, 1.1, 1.1.1, 1.2, 1.3, 1.3.1, 1.4, 1.4.1, 1.5, 1.6, 1.7, 1.7.1, 1.8, 1.9, 1.9.1, 2.0, 2.1, 2.2, 2.3, 2.4, 2.4.0.2, 2.5, 2.6, 2.6.1, 2.7, 2.7.0.1, 2.8, 2.9, 3.0, 3.0.1, 3.0.2, 3.0.3, 3.0.4, 3.0.5, 3.0.6, 3.1, 3.2, 3.3, 3.4, 3.5, 3.5.1, 3.6, 3.6.0.1, 3.6.0.2, 3.6.0.3, 3.6.0.4, 3.7, 3.7.0.1, 3.7.0.2, 3.7.1, 3.7.1.1, 3.7.1.2, 3.7.2, 3.7.3, 3.7.4, 3.7.5, 3.7.6, 3.8, 3.8.0.1, 3.8.0.2, 3.8.1, 3.8.2, 3.8.3, 3.8.4, 3.8.5, 3.8.6, 3.8.7, 3.8.7.1, 3.8.7.2, 3.8.7.3, 3.9, 3.9.0.1, 3.9.0.2, 3.9.0.3, 3.9.1, 3.9.2, 3.10, 3.10.0.1, 3.10.1, 3.10.2, 3.10.3, 4.0, 4.0.1, 4.0.2, 4.0.3, 4.0.4, 4.0.5, 4.0.6, 4.0.7, 4.1, 4.1.1, 4.1.2, 4.1.2.1, 4.2, 4.3, 4.3.1, 4.3.2, 4.3.3, 4.4, 4.4.0.1, 4.4.0.2, 4.5, 4.6, 4.6.0.1, 4.7, 4.7.0.1, 4.8, 4.9, 4.9.1, 4.10, 4.11, 4.11.1, 4.12, 4.12.1, 4.12.2, 4.12.3, 4.13, 4.13.1, 4.13.2, 4.13.2.1, 4.14, 4.15, 4.15.1, 4.15.2, 4.15.3, 4.15.4, 4.16, 4.16.1, 4.17, 4.17.1, 4.18, 4.18.1, 4.19, 4.19.1, 4.19.2, 5, 5.0.1, 5.1, 5.1.1, 5.2, 5.2.1, 5.2.2, 5.2.3, 5.3, 5.3.1 |
|---|---|
| Change log | CHANGELOG.markdown |
| Dependencies | array (>=0.3.0.2 && <0.6), base (>=4.5 && <5), base-orphans (>=0.5.2 && <1), bifunctors (>=5.1 && <6), bytestring (>=0.9.2.1 && <0.11), call-stack (>=0.1 && <0.5), comonad (>=4 && <6), containers (>=0.4.0 && <0.7), contravariant (>=1.3 && <2), distributive (>=0.3 && <1), exceptions (>=0.1.1 && <1), filepath (>=1.2.0.0 && <1.5), free (>=4 && <6), generic-deriving (>=1.10 && <2), ghc-prim, hashable (>=1.1.2.3 && <1.4), kan-extensions (>=5 && <6), mtl (>=2.0.1 && <2.3), nats (>=0.1 && <1.2), parallel (>=3.1.0.1 && <3.3), profunctors (>=5.2.1 && <6), reflection (>=2.1 && <3), semigroupoids (>=5 && <6), semigroups (>=0.8.4 && <1), tagged (>=0.4.4 && <1), template-haskell (>=2.4 && <2.17), text (>=0.11 && <1.3), th-abstraction (>=0.3 && <0.5), transformers (>=0.2 && <0.6), transformers-compat (>=0.4 && <1), type-equality (>=1 && <2), unordered-containers (>=0.2.4 && <0.3), vector (>=0.9 && <0.13), void (>=0.5 && <1) [details] |
| License | BSD-2-Clause |
| Copyright | Copyright (C) 2012-2016 Edward A. Kmett |
| Author | Edward A. Kmett |
| Maintainer | Edward A. Kmett <ekmett@gmail.com> |
| Revised | Revision 6 made by ryanglscott at 2021-05-16T13:35:46Z |
| Category | Data, Lenses, Generics |
| Home page | http://github.com/ekmett/lens/ |
| Bug tracker | http://github.com/ekmett/lens/issues |
| Source repo | head: git clone https://github.com/ekmett/lens.git |
| Uploaded | by ryanglscott at 2020-04-15T14:45:44Z |
| Distributions | Arch:5.2.3, Debian:4.18.1, Fedora:5.2.2, FreeBSD:4.12.3, LTSHaskell:5.2.3, NixOS:5.2.3, Stackage:5.2.3, openSUSE:5.2.3 |
| Reverse Dependencies | 1414 direct, 6342 indirect [details] |
| Downloads | 416529 total (925 in the last 30 days) |
| Rating | 3.0 (votes: 50) [estimated by Bayesian average] |
| Your Rating | |
| Status | Docs available [build log] Last success reported on 2020-04-15 [all 1 reports] |
Readme for lens-4.19.2
[back to package description]Lens: Lenses, Folds, and Traversals



This package provides families of lenses, isomorphisms, folds, traversals, getters and setters.
If you are looking for where to get started, a crash course video on how lens was constructed and how to use the basics is available on youtube. It is best watched in high definition to see the slides, but the slides are also available if you want to use them to follow along.
The FAQ, which provides links to a large number of different resources for learning about lenses and an overview of the derivation of these types can be found on the Lens Wiki along with a brief overview and some examples.
Documentation is available through github (for HEAD) or hackage for the current and preceding releases.
Field Guide
Examples
(See wiki/Examples)
First, import Control.Lens.
ghci> import Control.Lens
Now, you can read from lenses
ghci> ("hello","world")^._2
"world"
and you can write to lenses.
ghci> set _2 42 ("hello","world")
("hello",42)
Composing lenses for reading (or writing) goes in the order an imperative programmer would expect, and just uses (.) from the Prelude.
ghci> ("hello",("world","!!!"))^._2._1
"world"
ghci> set (_2._1) 42 ("hello",("world","!!!"))
("hello",(42,"!!!"))
You can make a Getter out of a pure function with to.
ghci> "hello"^.to length
5
You can easily compose a Getter with a Lens just using (.). No explicit coercion is necessary.
ghci> ("hello",("world","!!!"))^._2._2.to length
3
As we saw above, you can write to lenses and these writes can change the type of the container. (.~) is an infix alias for set.
ghci> _1 .~ "hello" $ ((),"world")
("hello","world")
Conversely view, can be used as a prefix alias for (^.).
ghci> view _2 (10,20)
20
There are a large number of other lens variants provided by the library, in particular a Traversal generalizes traverse from Data.Traversable.
We'll come back to those later, but continuing with just lenses:
You can let the library automatically derive lenses for fields of your data type
data Foo a = Foo { _bar :: Int, _baz :: Int, _quux :: a }
makeLenses ''Foo
This will automatically generate the following lenses:
bar, baz :: Lens' (Foo a) Int
quux :: Lens (Foo a) (Foo b) a b
A Lens takes 4 parameters because it can change the types of the whole when you change the type of the part.
Often you won't need this flexibility, a Lens' takes 2 parameters, and can be used directly as a Lens.
You can also write to setters that target multiple parts of a structure, or their composition with other lenses or setters. The canonical example of a setter is 'mapped':
mapped :: Functor f => Setter (f a) (f b) a b
over is then analogous to fmap, but parameterized on the Setter.
ghci> fmap succ [1,2,3]
[2,3,4]
ghci> over mapped succ [1,2,3]
[2,3,4]
The benefit is that you can use any Lens as a Setter, and the composition of setters with other setters or lenses using (.) yields
a Setter.
ghci> over (mapped._2) succ [(1,2),(3,4)]
[(1,3),(3,5)]
(%~) is an infix alias for 'over', and the precedence lets you avoid swimming in parentheses:
ghci> _1.mapped._2.mapped %~ succ $ ([(42, "hello")],"world")
([(42, "ifmmp")],"world")
There are a number of combinators that resemble the +=, *=, etc. operators from C/C++ for working with the monad transformers.
There are +~, *~, etc. analogues to those combinators that work functionally, returning the modified version of the structure.
ghci> both *~ 2 $ (1,2)
(2,4)
There are combinators for manipulating the current state in a state monad as well
fresh :: MonadState Int m => m Int
fresh = id <+= 1
Anything you know how to do with a Foldable container, you can do with a Fold
ghci> :m + Data.Char Data.Text.Lens
ghci> allOf (folded.text) isLower ["hello"^.packed, "goodbye"^.packed]
True
You can also use this for generic programming. Combinators are included that are based on Neil Mitchell's uniplate, but which
have been generalized to work on or as lenses, folds, and traversals.
ghci> :m + Data.Data.Lens
ghci> anyOf biplate (=="world") ("hello",(),[(2::Int,"world")])
True
As alluded to above, anything you know how to do with a Traversable you can do with a Traversal.
ghci> mapMOf (traverse._2) (\xs -> length xs <$ putStrLn xs) [(42,"hello"),(56,"world")]
"hello"
"world"
[(42,5),(56,5)]
Moreover, many of the lenses supplied are actually isomorphisms, that means you can use them directly as a lens or getter:
ghci> let hello = "hello"^.packed
"hello"
ghci> :t hello
hello :: Text
but you can also flip them around and use them as a lens the other way with from!
ghci> hello^.from packed.to length
5
You can automatically derive isomorphisms for your own newtypes with makePrisms. e.g.
newtype Neither a b = Neither { _nor :: Either a b } deriving (Show)
makePrisms ''Neither
will automatically derive
neither :: Iso (Neither a b) (Neither c d) (Either a b) (Either c d)
nor :: Iso (Either a b) (Either c d) (Neither a b) (Neither c d)
such that
from neither = nor
from nor = neither
neither.nor = id
nor.neither = id
There is also a fully operational, but simple game of Pong in the examples/ folder.
There are also a couple of hundred examples distributed throughout the haddock documentation.
Contact Information
Contributions and bug reports are welcome!
Please feel free to contact me through github or on the #haskell IRC channel on irc.freenode.net.
-Edward Kmett